词边界:\b
前言
词边界 \b 是一种检查,就像 ^ 和 $ 一样。
当正则表达式引擎(实现搜索正则表达式的程序模块)遇到 \b 时,它会检查字符串中的位置是否是词边界。
词边界\b
有三种不同的位置可作为词边界:
- 在字符串开头,如果第一个字符是单词字符
\w。 - 在字符串中的两个字符之间,其中一个是单词字符
\w,另一个不是。 - 在字符串末尾,如果最后一个字符是单词字符
\w。
一个小例子
例如,可以在 Hello, Java! 中找到匹配 \bJava\b 的单词,其中 Java 是一个独立的单词,而在 Hello, JavaScript! 中则不行。
js
console.log("Hello, Java!".match(/\bJava\b/)); // [ 'Java', index: 7, input: 'Hello, Java!', groups: undefined ]
console.log("Hello, JavaScript!".match(/\bJava\b/)); // null在字符串 Hello, Java! 中,以下位置对应于 \b:
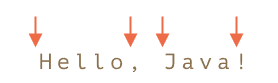
因此,它与模式 \bHello\b 相匹配,因为:
- 字符串的开头符合第一种检查
\b。 - 然后匹配了单词
Hello。 - 然后与
\b再次匹配,因为我们在o和一个空格之间。
js
// 匹配的四个空位置就是上图中四个箭头指的地方,\b并匹配的是位置,并不是字符
console.log("Hello, Java!".match(/\b/g)); // [ '', '', '', '' ]模式 \bJava\b 也同样匹配。但 \bHell\b(因为 l 之后没有词边界)和 Java!\b(因为感叹号不是单词 \w,所以其后没有词边界)却不匹配。
如下:
js
console.log("Hello, Java!".match(/\bHello\b/)); // [ 'Hello', index: 0, input: 'Hello, Java!', groups: undefined ]
console.log("Hello, Java!".match(/\bJava\b/)); // [ 'Java', index: 7, input: 'Hello, Java!', groups: undefined ]
console.log("Hello, Java!".match(/\bHell\b/)); // null
console.log("Hello, Java!".match(/\bJava!\b/)); // null
// 稍作更改就能匹配,最后一个是单词 a 所以会匹配到a\b
console.log("Hello, Java".match(/\bJava\b/)); // [ 'Java', index: 7, input: 'Hello, Java', groups: undefined ]\b 既可以用于单词,也可以用于数字。
例如,模式 \b\d\d\b 查找独立的两位数。换句话说,它查找的是两位数,其周围是与 \w 不同的字符,例如空格或标点符号(或文本开头/结尾)。
js
console.log("1 23 456 78".match(/\b\d\d\b/g)); // [ '23', '78' ]
console.log("12,34,56".match(/\b\d\d\b/g)); // [ '12', '34', '56' ]词边界
\b不适用于非拉丁字母词边界测试
\b检查位置的一侧是否匹配\w,而另一侧则不匹配 “\w”。但是,
\w表示拉丁字母a-z(或数字或下划线),因此此检查不适用于其他字符,如西里尔字母(cyrillic letters)或象形文字(hieroglyphs)。
总结
\b匹配的是一个位置,类似于^ $匹配的是文本的开头或结尾一样。
匹配到\b的位置,包含下面几种情况
- 字符串的开头,然后第一个字符是个单词符
\w - 在字符串的中间,其中一个是单词字符
\w,另一个不是。 - 在字符串的末尾,如果最后一个字符是单词符
\w
注意:词边界测试\b检查的是一侧是否匹配\w,而另一侧不匹配\w。但是\w表示拉丁字母a-z(或数字或下划线),因此它不适用于其他字符,如西里尔字母(cyrillic letters)或象形文字(hieroglyphs)。
js
let regexp1 = /\p{sc=Han}/gu; // returns Chinese hieroglyphs
let regexp2 = /\p{sc=Cyrillic}/gu; // returns 西里尔字符
let str = `Hello Привет 你好 123 _456`;
console.log(str.match(regexp1)); // [ '你', '好' ]
console.log(str.match(regexp2)); // [ 'П', 'р', 'и', 'в', 'е', 'т' ]
// 1. 词边界测试,测试 a-zA-Z 生效
console.log(str.match(/\b\w+\b/));
/*
[
'Hello',
index: 0,
input: 'Hello Привет 你好 123 _456',
groups: undefined
]
*/
// 2. 词边界测试,测试 数字 生效
console.log(str.match(/\b\d+\b/));
/*
[
'123',
index: 16,
input: 'Hello Привет 你好 123 _456',
groups: undefined
]
*/
// 3. 词边界测试,测试 下划线 生效
console.log(str.match(/\b_\d+\b/));
/*
[
'_456',
index: 20,
input: 'Hello Привет 你好 123 _456',
groups: undefined
]
*/
// 4. 词边界测试,测试 西里尔字符Cyrillic 不生效
console.log(str.match(/\b\p{sc=Cyrillic}+\b/u)); // null
console.log(str.match(/\p{sc=Cyrillic}+/u)); // Привет
/*
[
'Привет',
index: 6,
input: 'Hello Привет 你好 123 _456',
groups: undefined
]
*/
// 5. 词边界测试,测试 象形文字hieroglyphs 不生效
console.log(str.match(/\b\p{sc=Han}+\b/u)); // null
console.log(str.match(/\p{sc=Han}+/u)); // 你好
/*
[
'你好',
index: 13,
input: 'Hello Привет 你好 123 _456',
groups: undefined
]
*/